TRIDENT: Text-Free Data Augmentation Using Image Embedding Decomposition for Domain Generalization
Abstract
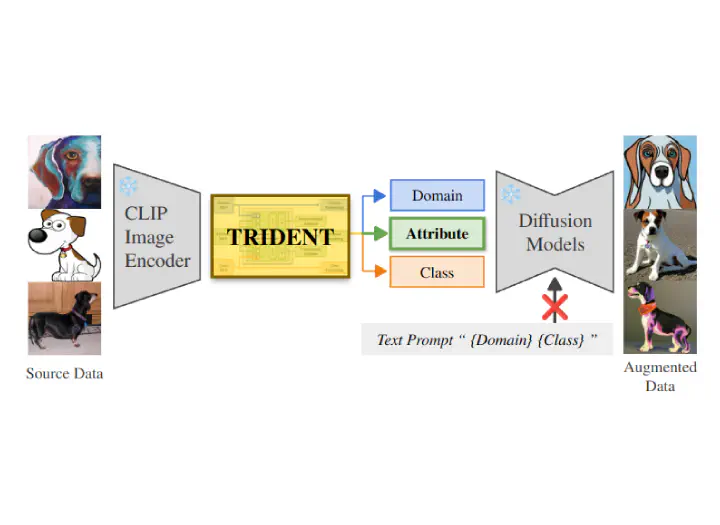
Deep learning has advanced vision tasks such as classification, segmentation, and detection. However, in real-world scenarios, models often encounter domains that differ from the ones seen during training, which can lead to substantial performance degradation. To mitigate the effects of distribution shifts, domain generalization (DG) aims to enable models to generalize effectively to unseen target domains. Recent DG approaches use generative models like diffusion models to augment data with text prompts. However, these methods rely on domain-specific textual inputs and require costly fine-tuning, which limits their scalability. We propose TRIDENT, a framework that overcomes these limitations by eliminating the need for text prompts and leveraging the linear structure of CLIP embeddings. TRIDENT decomposes image embeddings into three components—domain, class, and attribute—enabling precise control over semantic content. By reassembling each embedding component, we generate semantically valid and structurally coherent synthetic samples across domains. This allows efficient and diverse data synthesis without retraining diffusion models. TRIDENT operates through lightweight embedding-space manipulation, significantly reducing computational overhead. Extensive experiments on standard DG benchmarks (e.g., PACS, VLCS, and OfficeHome) demonstrate that TRIDENT achieves competitive or superior performance compared with existing approaches. Furthermore, qualitative evaluations and comprehensive analyses confirm that TRIDENT not only enables efficient and diverse data synthesis but also demonstrates the effectiveness of the proposed decomposition strategy.
Geunhyeok Yu
Ph.D. Student
My research interests include computer vision and neural representation learning.